
等闲的东说念主改动扫尾,优秀的东说念主改动原因,顶级高东说念主改动模子
你应该嗅觉到了,手机里的AI助手好像“开窍”了,比以前“智慧”点了。
以前,你问Siri、小爱同学“今天天气若何样”,它要转圈、联网,有时分还风马牛不相及。
当今,你断网喊它定个闹钟,它秒回。你写周报,AI帮你转头数据,险些无谓等。你开车,车机我方识别东说念主行说念,刹车比你还果决……。
你有莫得想过:为什么?
其实,不是你的网速变快了,也不是手机芯片性能翻倍了,而背后藏着一个你可能听过,但还没搞懂的期间——常识蒸馏。
它有点像“熬高汤”,把一大锅食材熬成一碗浓汤,体积小了,但精华齐在。
常识蒸馏,即是在作念这样的事儿——把大模子的“智慧劲儿”浓缩进一个小模子里,然后塞进你的手机、腕表、汽车等电子配置中。这样的话,即使断网,它们也颖慧活,秒回不卡顿。
今天,就和全球聊聊“常识蒸馏”这个话题。但愿小伙伴们阅读后,能有点得益。
1、什么是常识蒸馏?
回复这个问题前,我们先搞懂:什么是蒸馏。
来,先看张图,你笃定纯属。
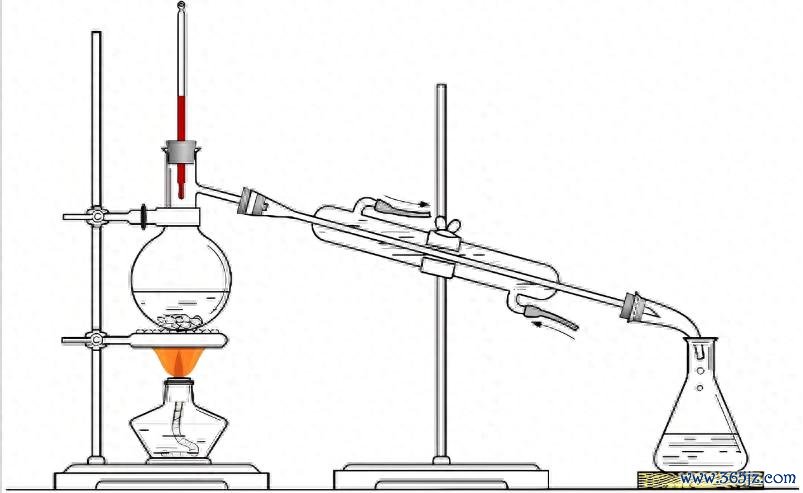
对,没错,这即是“实验室制取蒸馏水”。
没见过?不紧要,我再说个画面,你笃定见过。
一口大锅里熬着骨头汤,灶火渐渐煨着,水汽蒸腾,临了开云·体育锅里的汤从一大锅变成一小碗。尝一口,比原本的汤浓十倍。
为什么?
因为水分挥发掉了,留住来的全是骨头里的胶质、脂肪、香味——最精华的东西。
这即是蒸馏的本色:去除过剩的水分,保留最中枢的养分。
其实,常识蒸馏,干的是雷同的事情。只不外,它的“锅”是一台大模子,它的“骨头”是海量的参数和数据,它的“汤”是模子学到的判断才和谐想考边幅。
是以,常识蒸馏,即是用一个很是非的大模子当真挚,把它的“想考经过”索取出来,教给一个小模子当学生。学生学完后,体积小、跑得快、省电,还能不联网干活。但它的智慧进程,跟真挚差未几。
简便说,常识蒸馏,即是把大模子这些复杂的“贯通精华”,索取出来,浓缩进一个小模子里。
你可能会问:告成把大模子塞进手机里,不就行了?
天然不行。大模子太“重”了,一个GPT-4级别的模子,参数几千亿,体积几百个GB,手机根底装不下,就算装下了,跑一次要几秒钟,你等不起。何况它还终点耗电,跑几分钟手机就发烫。
是以,科学家才想了“蒸馏”这个办法:不让大模子躬行干活,让它当真挚,把我方的措施“教”给一个小模子。小模子学完之后,就可以去手机、电脑、汽车内部干活了。
你可能又要问:这是若何作念到的?
这样,你记忆一下我方上学时,学霸是若何给你讲题的。
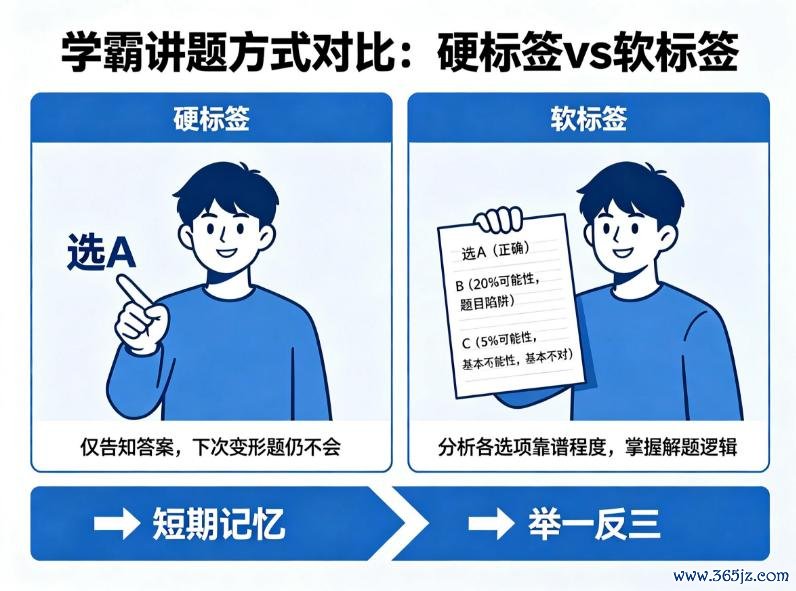
第一种情况:学霸告成告诉你“选A”,你记着了谜底。但下次碰到这说念题的变形题,你仍是不会。这叫硬标签。
第二种情况:学霸不光说选A,还分析“A正确,但B也有20%的可能性,因为题目里有个罗网;C唯独5%,基天职歧。”他把每个选项的“靠谱进程”齐讲给你听。这叫软标签。
你听完第二种,不仅知说念谜底,还知说念“B错在哪”、“C什么时分可能对”。以后即便碰到变形题、新题,你也能举一反三。
常识蒸馏,雷同第二种情况。
真挚模子(大模子)濒临一个问题,会给出一个概率散布:A有90%,B有7%,C有2%,D有1%。这个散布里藏着真挚模子的“想考踪迹”——哪些谜底昭彰对,哪些沾点边,哪些是罗网。学生模子(小模子)学的不是单一谜底“选A”,而是学这个概率散布——学“为什么B有7%的可能性”。这样一来,小模子诚然脑子小,但想问题的边幅接近大模子。
你的问题又来了,为什么非要学“概率散布”?
因为,施行全国很少有独一的正确谜底。你问AI“周末去哪玩”,它要是只给你一个谜底,简略不是你要的。
好的谜底,时时是在几个选项中衡量出来的。
小模子学了概率散布,就知说念“在什么情况下选B,在什么情况下选C”,碰到新问题也能举一反三。
是以,你看,常识蒸馏的本色:不是让模子变小,是让模子变智慧的边幅不变。
2、为什么大模子时期离不开蒸馏?
当今我们知说念了:常识蒸馏即是让大模子当真挚,把小模子教智慧。
你可能想问:“蒸馏期间”不是早就有了吗?若何这两年倏得到处齐在提?
没错,常识蒸馏的意见2015年就提倡了。但其时分的AI模子,还没这样大,算力也没这样贵,全球不以为它是“必需品”,也就没若何提。
大模子时期来了之后,一切齐不一样了,矛盾点立马凸显。
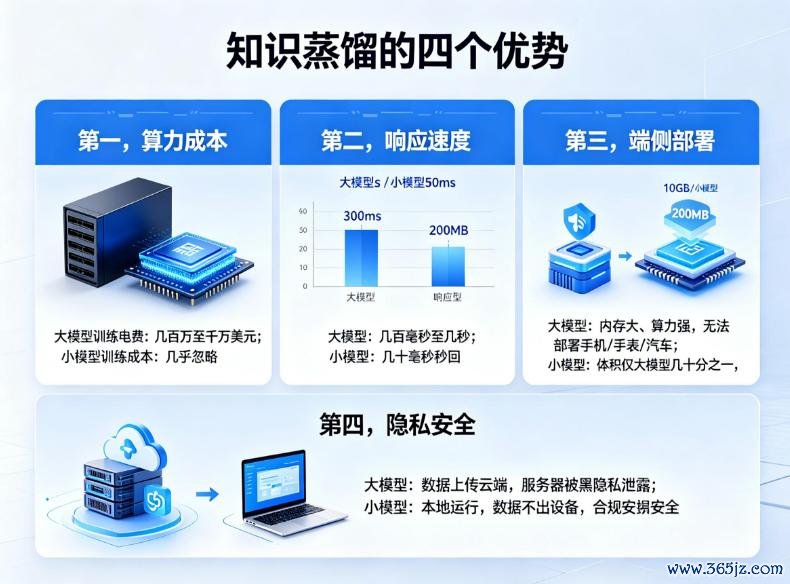
第一,是算力老本。
据机构测算,考验一个GPT-4级别的大模子,一次电费约几百万甚而上千万好意思元。而蒸馏后的小模子,考验老本险些可以忽略。据报说念,微软用蒸馏后的小模子Phi-3-mini替换了部分场景中的GPT-4,老本大幅下落。
金沙JinSha(中国)娱乐网入口因此,当你的模子大到一定进程,算力老本重压下,蒸馏就不是选拔题,是生计题。
第二,是反应速率。
大模子跑一次几百毫秒甚而几秒,你问它一句话,转圈半天才回。而小模子几十毫秒出扫尾,险些秒回。
要知说念,在及时对话、自动驾驶这些场景里,几秒的蔓延是十足不可袭取的。倒不是蒸馏更好用,而是慢的让你根底用不了。
你等得起的,用户等不起,你慢,他们立马就换。
第三,是端侧部署。
你的手机、腕表、汽车等电子配置,内存小、算力弱,根底装不下大模子。但用户想要的是离线也能用的AI,不想什么齐上传云表。
常识蒸馏后的小模子,体积唯独大模子的几颠倒之一,可以冒昧塞进配置里。据报说念,苹果通过蒸馏期间将谷歌的Gemini模子才调迁徙到iPhone端,竣事腹地运行。
第四,是诡秘安全。
以前AI靠云表,你的语音、相片齐得上传,万一就业器被黑,诡秘全裸奔。欧洲的GDPR、中国的《个东说念主信息保护法》,齐在收紧数据出境的截止。蒸馏让AI在腹地运行,数据不出配置,既合规又安全。
你的奥密,唯独你和手机知说念。
是以,常识蒸馏不是倏得“被拿起”的,而是大模子时期把上头这几个矛盾,同期推到了台前,且不得不处分。而常识蒸馏,巧合是能化解这些矛盾点。
也即是说,莫得蒸馏,大模子基本上只可在实验室里当排列。
3、蒸馏为什么能让小模子学到大模子的“真措施”?
要回复这个问题,那就不得不先说两个意见:温度T、暗常识。
这是什么玩意?
哎,等下,先别划走。这两个词听起来像哲学,其实是蒸馏内部最中枢的两个意见。
搞懂它们,你就能绝对剖判:蒸馏为什么能让小模子学到大模子的真措施。
前边我们说,大模子当真挚,要把我方的概率散布教给小模子。但你有莫得想过这个问题:有时分,大模子输出的概率散布,时常太“自信”,小模子时时会学偏。
什么理由?
举个栗子。
大模子判断全部题,可能输出:A有90%,B有7%,C有2%,D有1%。这个散布自己没错,但小模子一看:A 90%遥遥率先,开云·体育B、C、D险些可以忽略。于是,小模子就会以为“归正B、C、D基本无谓管”,扫尾它只学会了选A,没学会B和C到底差在哪。
这即是“大模子太自信,小模子学跑偏”。
科学家为了处分这个问题,引入了一个叫“温度T”的参数。调高温度,可以让大模子的概率散布变得更“平滑”。
原本90%、7%、2%、1%的散布,调高温度后可能变成70%、20%、8%、2%。这样一来,B、C、D的各别就显出来了,学生能明晰地看到:原本B也有一定预想,C偶尔也对,D基本没戏。
另外,那些被正确谜底“压下去”的低概率可能,有一个专门的名字叫暗常识。而这些暗常识之是以遑急,是因为它们时时是AI真确相连复杂全国的钥匙。
举个栗子。
假定你教一个小孩认动物。你给他看一张猫的图片,说“这是猫”。他记着了。然后你给他看一张老虎的图片,他可能会说“这是猫”,因为老虎也有尖耳朵、长胡子、毛茸茸。他只学了“猫的特征”,没学“猫和老虎的区别”。这即是只给正确谜底的局限。
但你要是换一种教法:你指着猫说“这是猫,概率90%”,又指着老虎说“这个是老虎,但它长得有点像猫,是以也有20%可能是猫”,再指着狗说“这个是狗,跟猫不像,唯独1%可能是猫”。小孩听到的不仅仅“哪个是猫”,还知说念了“老虎有点像猫,狗少量齐不像”。下次他见到一只狸花猫,也能认出来,因为它介于猫和老虎之间。
这里的“老虎也有20%可能是猫”,即是暗常识。它告诉学生的不是“正确谜底”,而是“正确谜底的鸿沟在哪”。莫得这个鸿沟,学生就只会死记硬背,碰到没见过的东西就懵了。
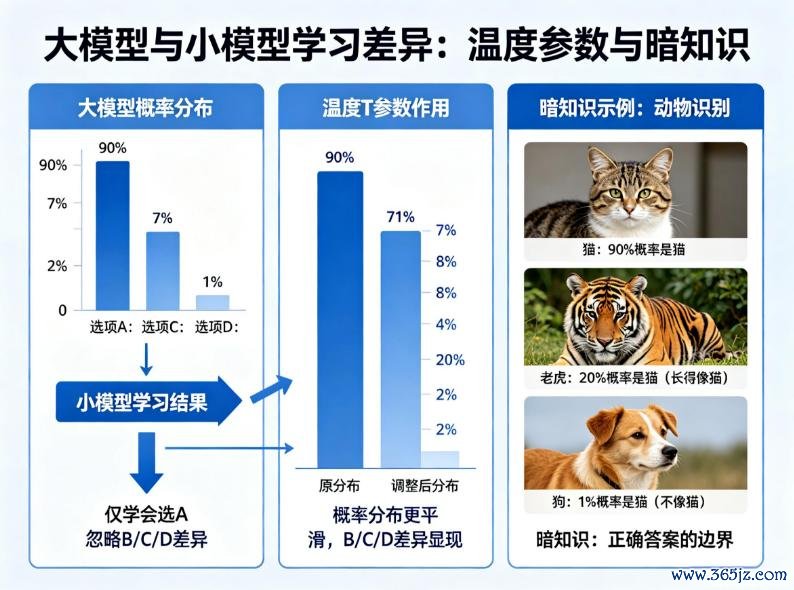
常识蒸馏作念的恰是这件事:把大模子对每个选项的“概率判断”全部教给小模子,包括那些低概率的、看似“无理”的谜底。因为那些低概率里,藏着差别“对”和“差未几对”的重要信息。
因此,温度T的作用,即是让大模子“放软口吻”,把暗常识暴领略来。这样小模子学到的,就不再是干巴巴的谜底,而是谜底背后“对”和“差未几对”的衡量。
4、蒸馏有什么争议?
蒸馏很深广,但它带来的发愤也不少。最扯后腿的争议,即是“偷师”。
为了幸免被关小黑屋,具体争议,全球可以网上去搜一堆。
这里,我只简便形色约莫经过。
曩昔两年,有些公司用蒸馏期间,拿开源模子去“师法”顶尖闭源模子。比如,让某闭源模子生成多数“问题-谜底”数据,然后再用这些数据考验我方的小模子。
这样,老本极低,考验出来的模子成果还可以。
闭源大模子公司看了,怒了:我花几亿好意思元考验的模子,你花几千好意思元就师法了,你还有莫得行状说念德。
于是,全球顶尖的闭源大模子公司初始联手反制。
据报说念,这些闭源模子公司通过分享安全信息的边幅,识别抗拒性蒸馏举止。但特理由的是,这些闭源模子公司我方也没少干蒸馏。某闭源模子因从盗版网站下载超700万本书考验我方的模子,抵偿了十几亿好意思元。
你看,一边喊着别东说念主不成“偷”,一边我方在“偷”,挺拧巴的。
除了“偷师”的争议,还有更深的问题——“潜意志学习”。
本年4月,有项磋商标明:在模子蒸馏经过中,“真挚”模子的举止特征可以通过语义上完全无关的数据,暗暗传递给“学生”模子。
也即是说,就算你严格筛选考验数据,“真挚”模子里潜在的偏见、甚而坏心倾向,也会鸦雀无声地传给“学生”模子。磋商东说念主员称之为“潜意志学习”。
这有点像“嫡亲养殖”,数字全国的“嫡亲养殖”。也即是,模子之间相互学,不单学会优点,还在鸦雀无声中放大和传承相互荫藏的弱势。
这项发现,让AI安全领域集体出了伶仃盗汗。因为,当总共模子齐从吞并个“真挚”模子学习,那无理就会被长久固化。
5、蒸馏正在若何改动AI的形式?
聊完结蒸馏的旨趣和争议,你可能想问:这东西跟我有什么关系?
联系系,因为它正在暗暗改写AI的游戏规章。
什么理由?别急,听我讲。
以前,AI的玩法是“越大越好”。
各家拚命堆鸿沟,因为全球默许:参数越多,算力越强,谁家的模子就越智慧,越是非。
但这个逻辑有个致命问题——大模子太贵、太慢、太重,只可待在云表,等闲东说念主只可通过API接口跟它对话。
当今,蒸馏把这个逻辑冲突了。
它让大模子的价值不再局限于“只可我方提供就业”,而是可以“复制”出无数个小模子,塞进手机、腕表、汽车、家电等配置。
一个顶级大模子可以当真挚,蒸馏出成百上千个学生,分散到全国的各个边缘。这样,大模子住在云表,小模子揣进你的兜里。
这意味着什么?
两件事。
第一,AI会变得无处不在。
你不再需要联网去调用一个远处的模子,你手里的配置我方即是一个小模子。它可能莫得“真挚”模子那么智慧,但够用、快、巧妙。
这就像当年的规划机从大型机变成个东说念主电脑,AI也在经历一样的“民主化”。
每个东说念主口袋里的AI,才是真确的AI。
第二,竞争形式变了。
曩昔,谁的大模子参数多,谁就有言语权。当今,参数多不一定赢,重要是你能不成培养出最实用的“学生”。
这对创业公司来说,是契机。因为,他们不需要我方考验大模子,只需要蒸馏出一个垂直场景的小模子,就能作念出好居品。
对巨头来说,是挑战。因为,他们的大模子再智慧,要是蒸馏出来的小模子不好用,用户也不买账。
形式变,意味着不是唯独造出“巨无霸”的东说念主,才有履历参赛。
但硬币还有另一面。
要是总共东说念主齐去蒸馏吞并个最智慧的“真挚”模子,那总共小模子的想维边幅就会趋同。也即是说,你手机里的AI和你一又友电脑里的AI,本色上是一个模子刻出来的。
这会带来什么问题?
昭着,各种性会下落,翻新会受阻。
要是总共AI齐认为“A是独一正确谜底”,那些边缘的、非主流的可能性就会被绝对淘汰。
一群一模一样的智慧东说念主,远不如一个会犯错的天才有价值。
是以,蒸馏是把双刃剑。我们在享受它带来的苟简和高效的同期,也得把稳它可能变成的“想想单一”。
总之,期间的主义,从来不是由期间自己决定的,而是由使用期间的东说念主决定的。
6、临了,粗谈几点看法。
嚯,连气儿聊完本期的话题,状况!
临了,对于该话题,粗谈我方的几点看法。
一、常识蒸馏的本色,不是把大模子“压小”,而是把大模子的“判断逻辑”索取出来,传给小模子。
参数可以缩,但判断的颗粒度不成丢。大模子濒临一个问题给出的概率散布,比它的最终谜底更有价值。蒸馏作念的最中枢的一件事,即是把这种散布里的“暗常识”教给学生。莫得这一步,小模子学到的恒久仅仅表率谜底,而不是想考边幅。
真确的常识,藏在概率的破绽里。
二、蒸馏正在改动AI的竞争形式。
曩昔,谁的大模子参数多、算力强,谁就有言语权。当今,一个大模子可以蒸馏出无数个小模子,分散告成机、汽车、手内外。
价值不再只集中在云表,而是被分发到边缘。
这意味着,异日的竞争不仅仅看谁能造出最智慧的“真挚”,还要看谁能培养出最实用的“学生”。这对创业公司来说是契机,对巨头来说是挑战。不是唯独造出巨无霸的东说念主才有履历参赛。
三、蒸馏有一个深层悖论:期间越追求“正确”,留给“随机”的空间就越小。
我们追求着力,把模子变小、变快、变省电,但同期也在把贯通的各种性少量点滤掉。
那些被蒸馏掉的低概率谜底,那些在高温下被平滑掉的边缘散布,很可能即是冲突旧例、产生新想想的种子。
期间越追求“正确”,留给“随机”的空间就越小。这个问题,比“偷师是否侵权”更值得警惕。
着力的代价,时时是可能性。
四、期间不会我方停驻,但东说念主可以保捏表露。
蒸馏是个好用具,但它不是全能钥匙。知说念什么时分该用蒸馏,什么时分该保留大模子的好意思满想考,甚而什么时分该让东说念主我方来作念决定——这才是独霸期间的才调,而不是被期间牵着走。
用具恒久在逾越,但使用用具的东说念主,才是决定主义的重要。
临了,一句话:期间可以被蒸馏,但想考不成;浓缩得了常识,浓缩不了判断;用具可以变小,但独霸用具的东说念主,不成变懒。





